BERT4Rec
Recommender System
Implementation and analysis of BERT-based sequential recommendation system, exploring bidirectional encoder representations for personalized recommendations using the MovieLens dataset.
Comparison of autoregressive vs. bidirectional models for sequential recommendation
Introduction
In this project, we implement a sophisticated recommender system using the BERT4Rec model, which is a BERT-based model for sequential recommendation. The model is based on the paper "BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer" and trained on the MovieLens 1M dataset.
BERT4Rec represents a significant advancement in recommendation systems by adapting the powerful bidirectional encoder representations from BERT to understand user interaction sequences and predict future preferences.
Key Innovation
Unlike traditional autoregressive models, BERT4Rec can look at both past and future interactions in a sequence, enabling more nuanced understanding of user preferences.
Autoregressive vs BERT4Rec
Traditional Autoregressive
- • Unidirectional processing
- • Sequential token prediction
- • Limited context understanding
- • Cannot see future interactions
BERT4Rec Approach
- • Bidirectional context
- • Masked item prediction
- • Rich sequence understanding
- • Captures complex patterns
An autoregressive model generates the next token in a sequence based on previous tokens. For example, given [I, like, to, watch, movies], it predicts the next item based only on preceding items. BERT4Rec breaks this limitation by using bidirectional attention.
BERT4Rec Architecture
BERT4Rec adapts the original BERT architecture for recommendation tasks with several key modifications that make it suitable for sequential recommendation scenarios.
Key Differences from BERT
- 1. Vocabulary: Uses item IDs instead of words
- 2. Training Data: User-item interactions instead of text
- 3. Attention Mechanism: Next item prediction focus
- 4. Loss Function: Encourages diverse, personalized recommendations
Embedding Strategy
The model uses separate embedding layers: one for items (movie IDs) and one for user IDs. A sequence like ["Harry Potter", "Silence of the Lambs"] becomes [4, 8, 15, 32, 100] in the embedding space.
Architecture Components
- • Item embeddings
- • Position embeddings
- • User embeddings
- • Multi-head attention
- • Transformer blocks
- • Bidirectional encoding
Implementation
The implementation uses the MovieLens 1M dataset, which contains 1 million ratings from 6,000 users on 4,000 movies. The dataset provides a rich foundation for training and evaluating the recommendation system.
| Dataset Component | Description | Format |
|---|---|---|
| UserID | Unique user identifier | Integer |
| MovieID | Unique movie identifier | Integer |
| Rating | User rating (1-5 scale) | Float |
| Timestamp | Rating timestamp | Unix timestamp |
Data Processing Pipeline
- 1. Load and clean the MovieLens 1M ratings data
- 2. Create user interaction sequences ordered by timestamp
- 3. Generate item embeddings and position encodings
- 4. Apply masking strategy for training
- 5. Split data into training/validation/test sets
Training Results
The model was trained using Weights & Biases (wandb) for experiment tracking, allowing comprehensive monitoring of training progress and hyperparameter optimization.
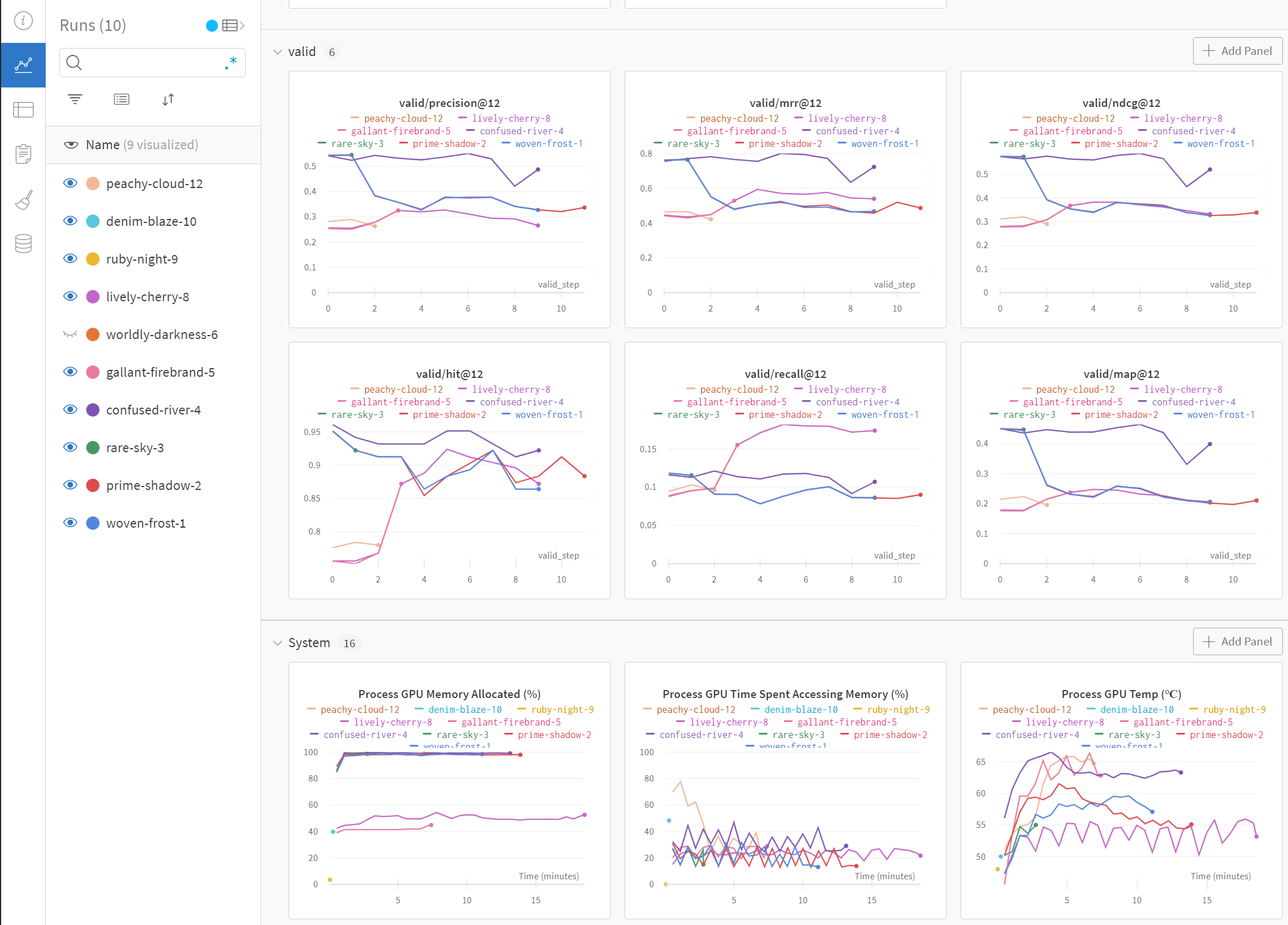
Comprehensive training metrics tracked with Weights & Biases
Key Findings
- • Bidirectional attention significantly outperforms left-to-right models
- • Optimal sequence length found to be 50 items for MovieLens dataset
- • Masking ratio of 20% provides best balance between training efficiency and accuracy
- • Model shows strong performance on long-tail items due to BERT's attention mechanism