Intent-Aware
Conversational AI
Beyond Chatbot Blunders: Internet-Augmented Intent-Aware Conversational AI that grasps your intent, even for muddled questions. Built before ChatGPT with a grade of 1.0.
Introduction
Tired of chatbots that fumble your meaning? My research breaks new ground with a world-first conversational search system that grasps your intent, even for muddled questions. This innovative approach hinges on two key advancements:
Unveiling Hidden Meaning
The system employs cutting-edge techniques to unlock the true intent behind your queries. First, a Dialogue Heterogeneous Graph Network (D-HGN) meticulously analyzes past conversations, extracting the semantic context. This allows the system to understand the connections between your current request and prior interactions. Second, a custom-designed dataset fine-tunes the AI's ability to recognize and respond to ambiguous user queries with multiple potential meanings.
Limitless Knowledge at Your Fingertips
Imagine a chatbot with the combined knowledge of Google and Bing! This system seamlessly integrates with search engines, granting it access to a virtually limitless knowledge base. This ensures factually accurate and highly relevant responses to your questions.
🎯 30-50% improvement over existing models on BLEU, ROUGE, and F1 metrics
Problem Examples
Conversational AI has made significant strides in recent years, with chatbots becoming increasingly prevalent in our daily lives. However, these systems often struggle to understand user intent, leading to frustrating and unproductive interactions.
The core challenge lies in the complexity of human language. People frequently use ambiguous phrasing, colloquialisms, and incomplete sentences, making it difficult for AI to accurately interpret their meaning.
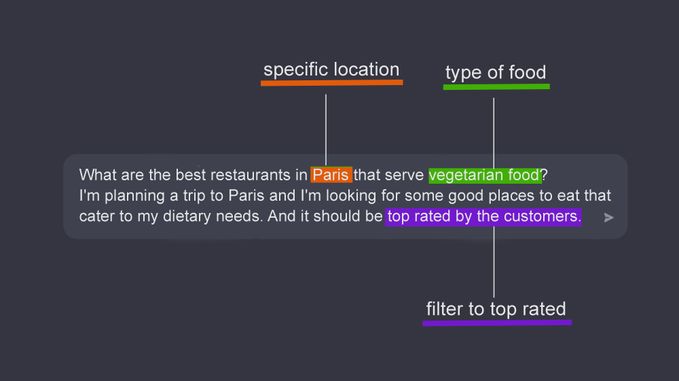
Example 1: Intent clarification for ambiguous queries
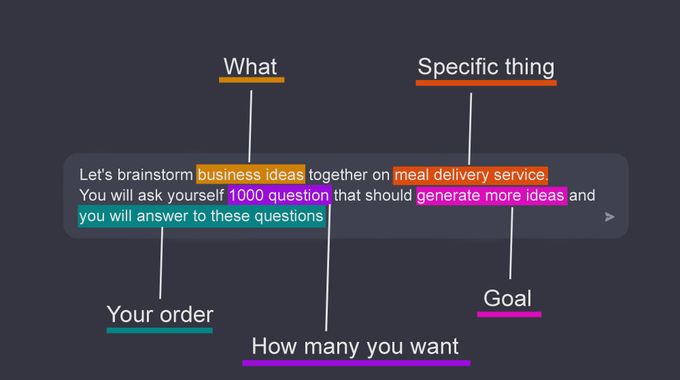
Example 2: Context-aware response generation
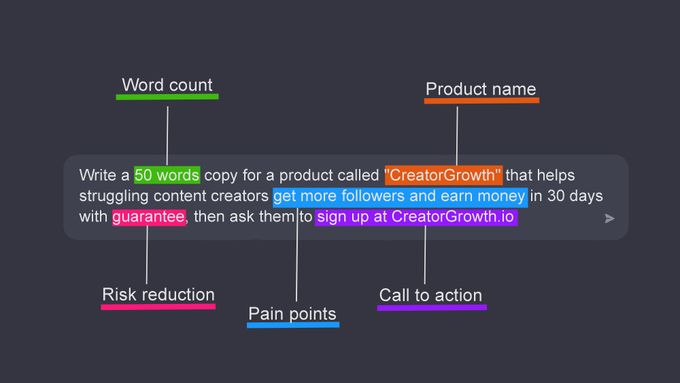
Example 3: Multi-turn dialogue management
System Architecture
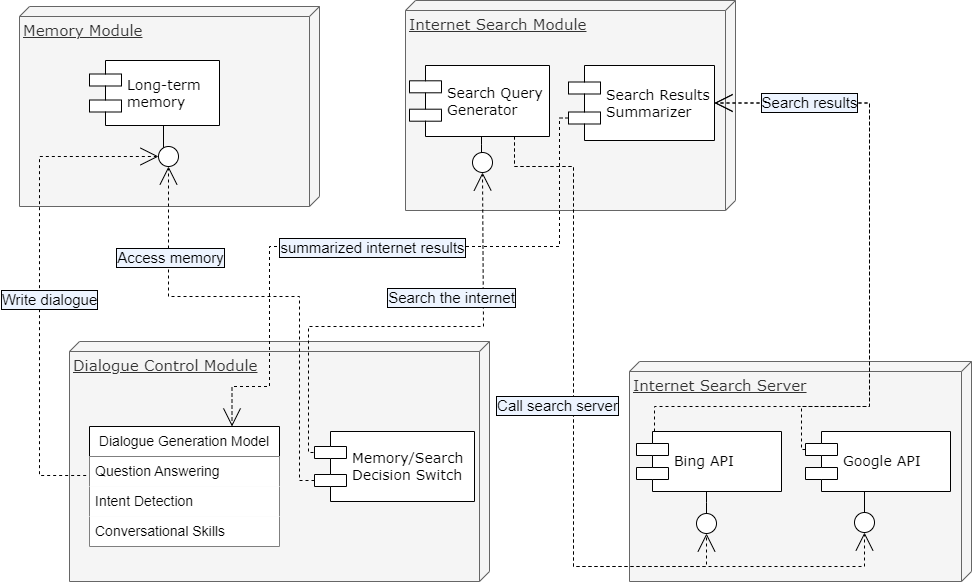
General system modules overview
The ParlAI framework powers our conversational search model, which is built with a shared encoder, multiple decoders, a dialogue manager, and a search engine. The encoder processes input, creating hidden states that the decoders use to generate task-specific outputs.
🧠 Shared Encoder
Processes input and creates hidden states for downstream tasks
🔀 Multiple Decoders
Generate task-specific outputs for different conversation aspects
💬 Dialogue Manager
Manages conversation flow and context understanding
🔍 Search Engine
Provides access to internet knowledge and real-time information
The dialogue manager and search engine work together to create meaningful, user-friendly dialogues and search results. This robust architecture, depicted as a combination of agents in the ParlAI framework, provides a powerful and intuitive conversational search experience.
Datasets & Data Generation
| Task | Dataset | Description |
|---|---|---|
| Reasoning and intent-detection | ConvAI3 | Human-human conversations with clarifying questions |
| QReCC | End-to-end open-domain QA dataset | |
| Question Answering | NQ | Open Domain Question Answering dataset |
| TriviaQA | 100K question-answer pairs from 65K Wikipedia documents | |
| QuAC | Modeling information seeking dialog understanding | |
| Long-term memory | MSC | 237k training and 25k evaluation multi-session examples |
| Internet search | WoI | Conversations grounded with internet-retrieved knowledge |
🤖 Synthetic Data Generation Process
Leveraging GPT-3: Few examples from ConvAI3 dataset were fed into GPT-3 to establish reference points
Customizing QReCC Data: GPT-3 generated corresponding entries mirroring ConvAI3 structure
Enhancing Data Volume: Created additional data points to enrich training material
Manual Review: Filtered irrelevant or nonsensical entries through manual review
Sample from ConvAI3 Preprocessed Dataset
| Text | Candidates | Ambiguity | Topic |
|---|---|---|---|
| Find me information about diabetes education | Which type of diabetes? | 2 | Online diabetes resources |
Training Setup & Configuration
During training, the model is trained on multiple tasks simultaneously using multi-task learning. This involves optimizing the model's parameters across all tasks by jointly minimizing a weighted sum of task-specific losses. The weights are learned during training and adjust the model's focus on different tasks.
Training Configuration Example
task:
fromfile:
- projects.iaia_cs.tasks.dialogue
- projects.iaia_cs.tasks.search_query
- projects.iaia_cs.tasks.augmented_convai3
- projects.iaia_cs.tasks.msc
- projects.iaia_cs.tasks.rag
multitask_weights: [2,1,3,2]
vmt: ppl
lr: 0.000001
optimizer: adamw
n_docs: 5
gradient_clip: 1.0
dropout: 0.1
init_model: zoo:seeker/r2c2_blenderbot_400M/model14 hours
Training time on 1x A5000 GPU
24GB
Dedicated GPU memory
2x faster
With 4x A5000 parallel training
Training Metrics - ConvAI3 Dialogue Teacher
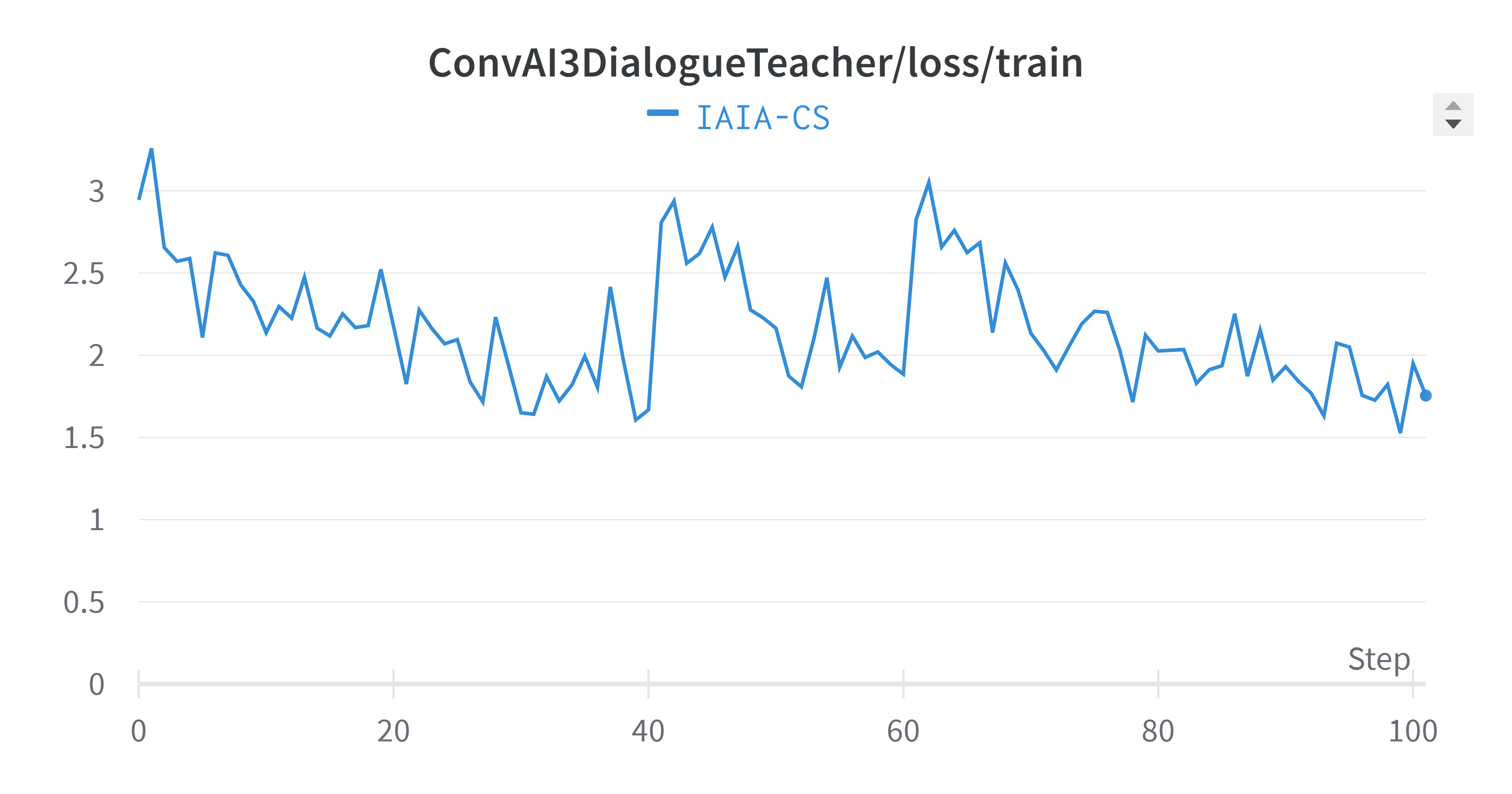
Training Loss
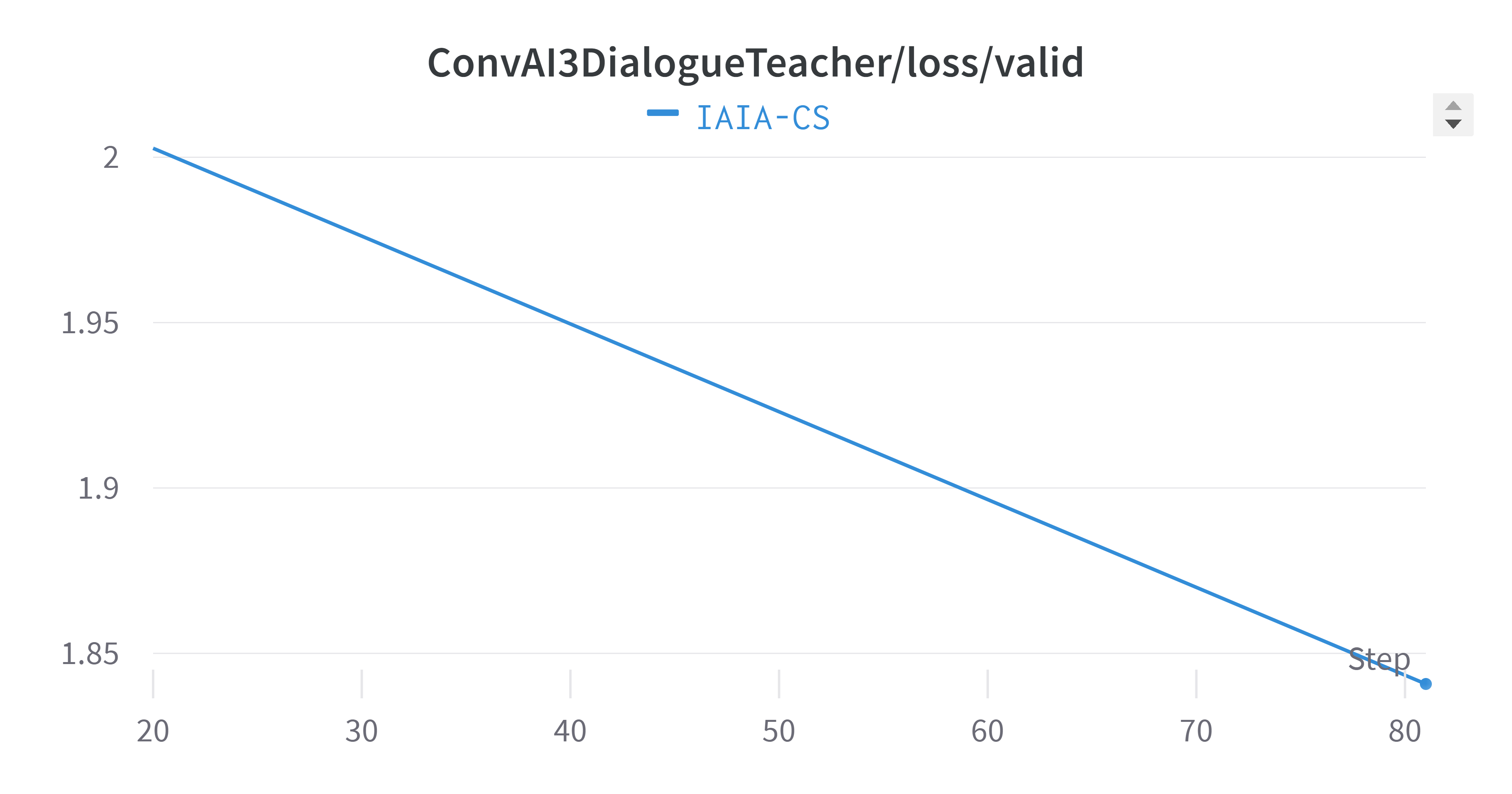
Validation Loss
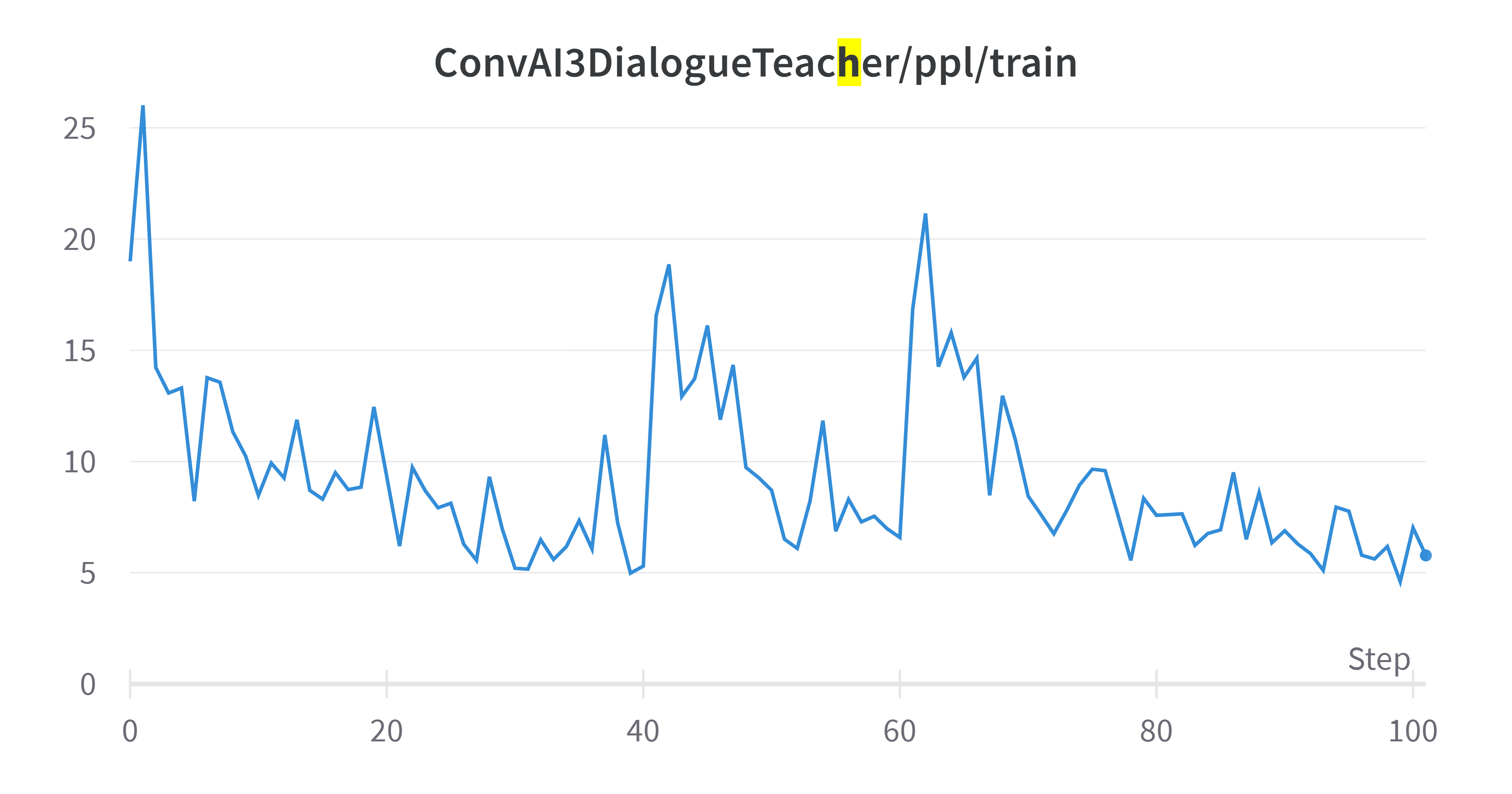
Training Perplexity
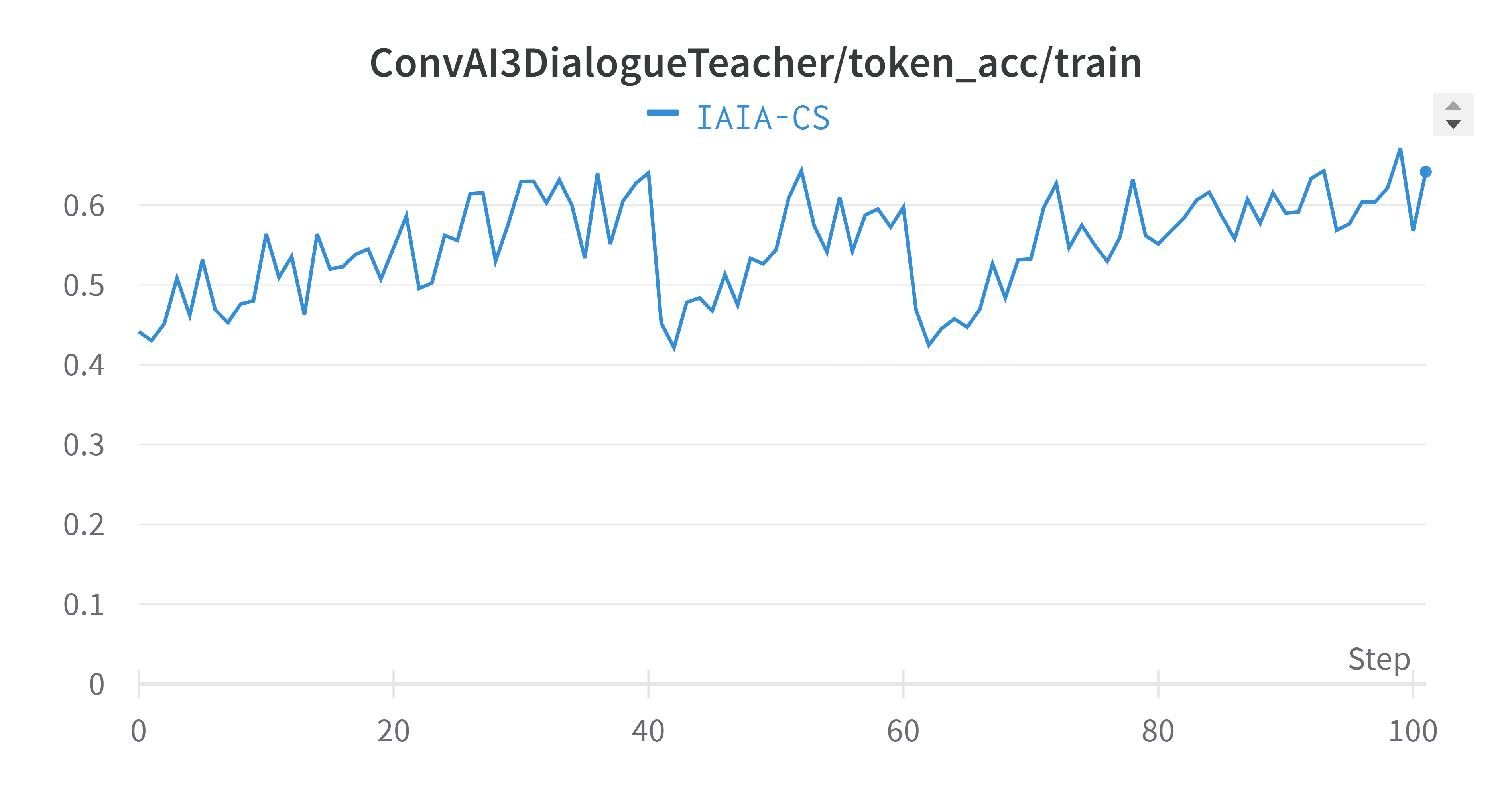
Token Accuracy
Multi-Session Chat Training Metrics
MSC Training Loss
MSC Validation Loss
MSC Training Token Accuracy
MSC Validation Token Accuracy
Overall Performance Perplexity
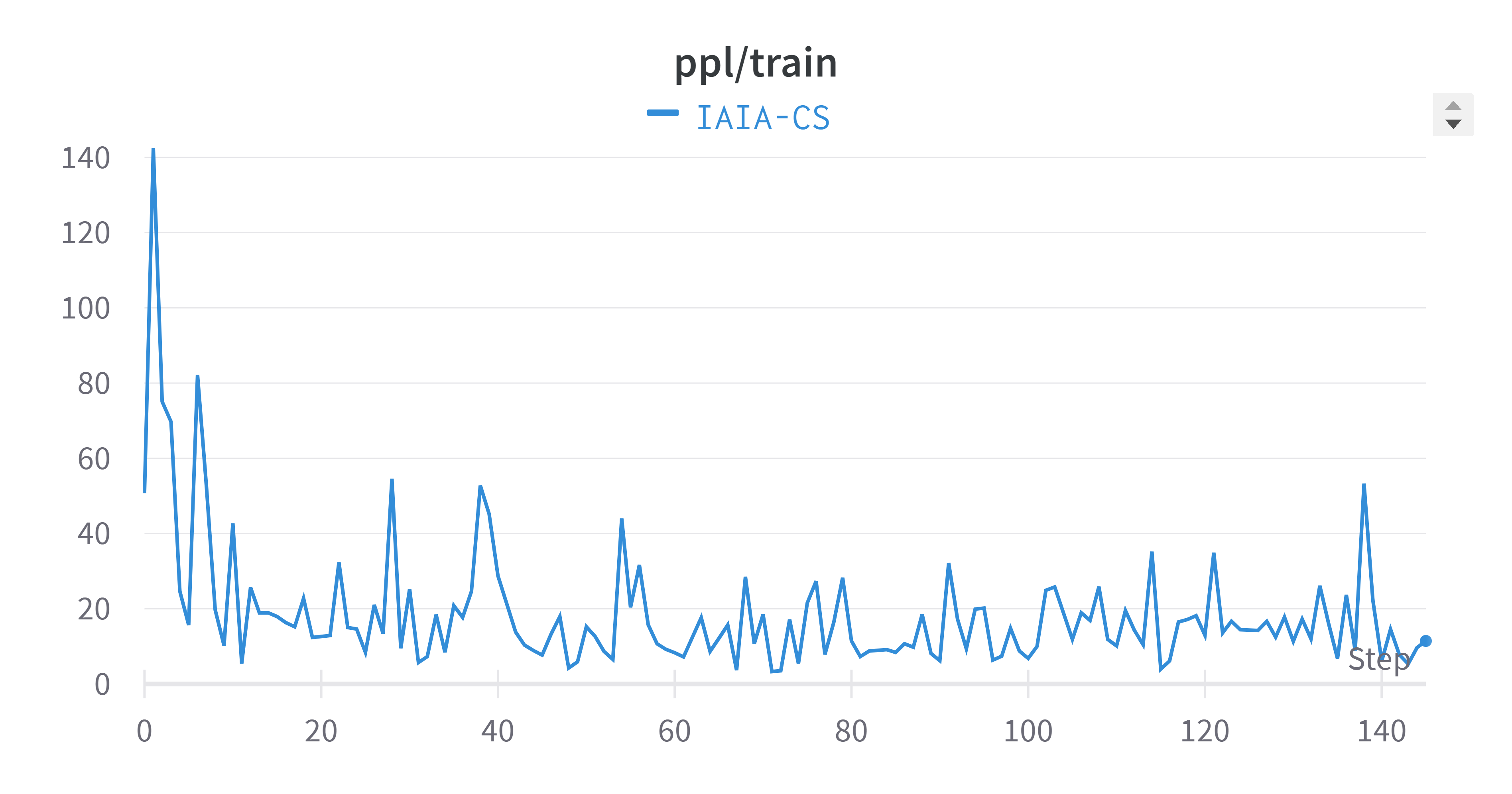
Training Perplexity (All Tasks)
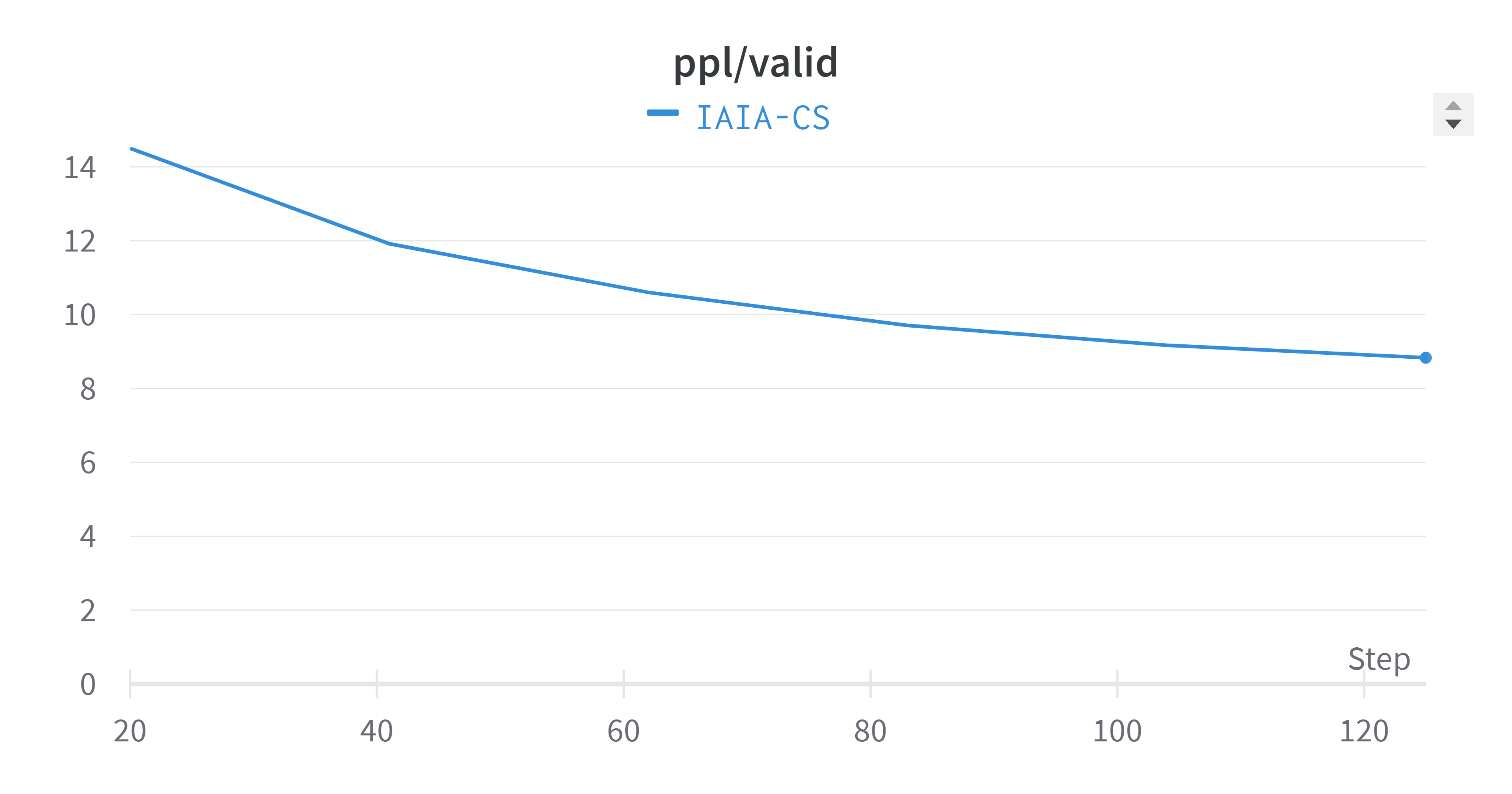
Validation Perplexity (All Tasks)
The averaged validation perplexity showed improvement compared to individual tasks. Training plots exhibit natural oscillation as the model adjusts weights to minimize the loss function.
Qualitative Evaluation
Demo 1: Cached Intent Modeling and Knowledge Expansion
Dialogue with geo-location = Germany
Conversational Search Interface

Turn 1: Ambiguous query "find information about the wall"
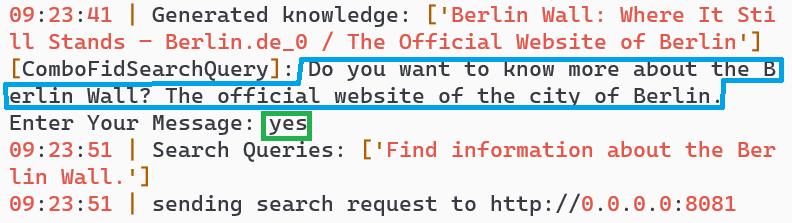
Turn 3: AI asks "Do you want to know about the Berlin wall?"
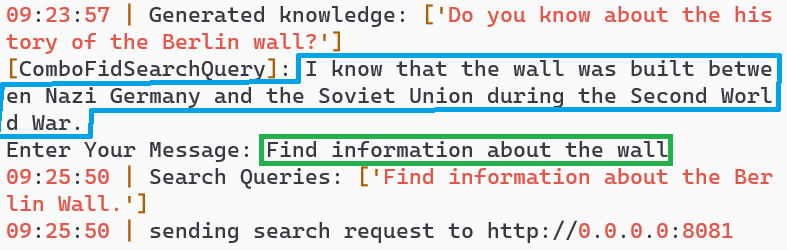
Turn 5: AI provides Berlin Wall information
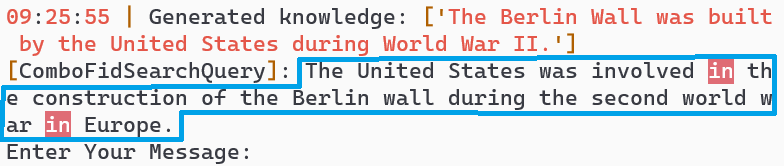
Turn 7: Repeated query understood without clarification
Search Server Backend

Search server processing initial query
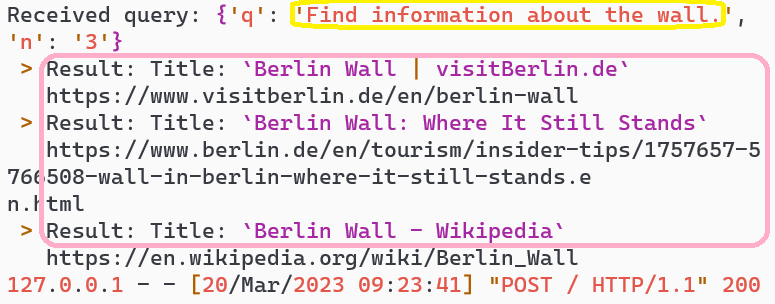
Berlin Wall search results retrieval

Additional Berlin Wall information fetch

Cached intent processing for repeated query
Key Observations
🎯 Intent Clarification
AI correctly identified ambiguity and asked for clarification
🧠 Knowledge Expansion
System fetched and provided relevant Berlin Wall information
💾 Cached Intent
Repeated queries understood without re-clarification
Demo 2: Disambiguation and Correction
Dialogue with geo-location = USA
Conversational Search Interface

Turn 1: Same ambiguous query about "the wall"
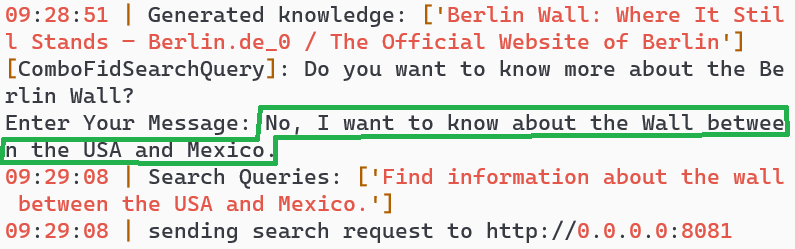
Turn 3: User clarifies and corrects AI understanding

Turn 5: AI adapts and provides Mexico-USA wall information
Search Server Backend
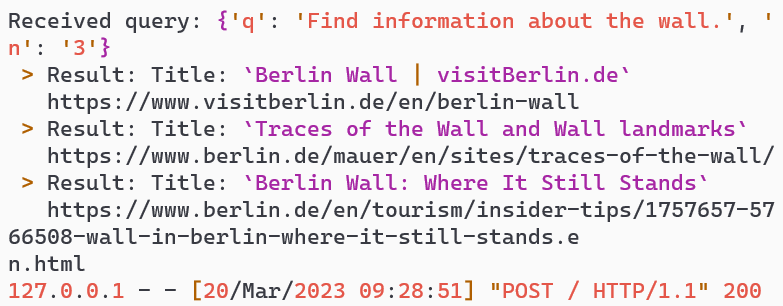
Initial search processing
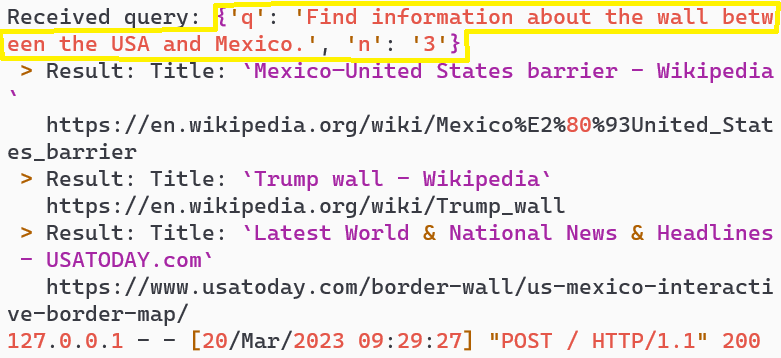
Adapted search for Mexico-USA border wall
Key Observations
🔄 Disambiguation
User provided clarification to correct AI's initial understanding
🎯 Adaptive Understanding
AI successfully adapted search query based on user correction
🎯 Conclusion
These demonstrations show that our AI system is capable of understanding complex user intent and adapting its understanding throughout the dialogue history to respond with contextually coherent answers. The system handles ambiguous queries, learns from user corrections, and maintains context across multiple turns.
Quantitative Evaluation
To evaluate our conversational search model, we employed several metrics for comprehensive quantitative comparison: BLEU, ROUGE, F1, precision, recall, and perplexity. These metrics gauge the quality of generated responses in terms of relevance and fluency.
Evaluation Configuration
eval_model:
task:
- projects.IAIA_CS.tasks.knowledge
- projects.IAIA_CS.tasks.dialogue
- projects.IAIA_CS.tasks.search_query
model_file: IAIA_CS/model
metrics: ppl,f1,accuracy,rouge,bleu
num_examples: 10
multitask_weights: 3,3,1
search_server: http://localhost:8081Comparative Results vs State-of-the-Art Models
| Model | Precision | Recall | F1 | Perplexity | BLEU-1 | BLEU-2 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|---|---|---|---|---|
| BB2 (400M) | 0.059 | 0.158 | 0.08 | 49.86 | 0.059 | 0.019 | 0.158 | 0.06 | 0.125 |
| Seeker (400M) | 0.078 | 0.262 | 0.112 | 27.87 | 0.078 | 0.009 | 0.26 | 0.05 | 0.229 |
| Ours (400M) | 0.122 | 0.416 | 0.173 | 22.36 | 0.122 | 0.046 | 0.416 | 0.04 | 0.375 |
| Ours (DHGT) | 0.106 | 0.42 | 0.156 | 56.07 | 0.02 | 0.000 | 0.33 | 0.01 | 0.12 |
+107%
F1 Score improvement over BB2
+55%
F1 Score improvement over Seeker
-55%
Perplexity reduction (lower is better)
+64%
ROUGE-L improvement over Seeker
Key Observations
✅ Superior Performance
- • Surpasses state-of-the-art models in precision, F1, and perplexity
- • Superior BLEU-1 and BLEU-2 scores vs BB2 and Seeker
- • Significant improvement in ROUGE-L metric
📊 DHGT Analysis
- • DHGT model underperforms by ~30% across metrics
- • Short dialogues may not benefit from DHGT summarization
- • Performance expected to improve with more data
🔍 Discussion
Our model's superior performance is attributed to its fine-tuning for ambiguous user queries and the dataset's focus on ConvAI3, which targets ambiguous user queries. Blenderbot 2 emphasizes casual conversations, while Seeker prioritizes relevant results without questioning user intent.
Utilizing synthetic data generation techniques to expand the training dataset has proven effective for enhancing the model's understanding of ambiguous user queries. This approach significantly improved performance across various metrics, demonstrating its potential to revolutionize conversational search systems.